
背景
PHUSEが10月に公開したTerminology Harmonisation in Data Sharing and Disclosure Deliverables Guidance V2 (Version 2)とTerminology Harmonisation in Data Sharing and Disclosure Deliverables Terms and Definitions (Version 2)いうドキュメントにて、匿名化(Anonymisation)、仮名化(Pseudonymsation)、非識別化(De-identification)などの用語を整理していました。
確かにこのあたりの用語の違いは、国・地域や立場によっても異なることが多いです。このPHUSEの報告書では、複数の規制当局やISOといった標準化機関などの文書をもとに整理したようなので、その内容を確認してみました。
非識別化(De-identification)の定義
日本の個人情報保護法のような法律にはない用語で、匿名化や仮名化との違いが分かりにくい用語ですが、PHUSEでは以下のように定義しています。
A general term for any process of removing the association between a set of identifying data and a data subject present in data or documents. The association between data and subject is removed by modifying (e.g. removing, obscuring, aggregating, altering) identifiable information in structured data and documents. The association between data and subject is removed by modifying (e.g. removing, obscuring, aggregating, altering) identifiable information in structured data and documents.
Terminology Harmonisation in Data Sharing and Disclosure Terms and Definitions (version 2)
「データやドキュメントに含まれる、識別データ(組み合わせも含めた一連のデータ項目)とデータ主体(本人)との間の関連性を取り除くプロセスの総称」といった感じでしょうか。また後段にて、そのデータとそのデータに含まれる本人との関連性を取り除く方法として、識別データ項目の削除、不明瞭化、集約化、(データ値の)変更が例示されています。
本人との関連性を取り除くためにデータを削除したり変更したりする識別データは、直接識別子と準識別子の両方を含み、氏名、電話番号、固有IDなどの直接識別子は削除(固有IDの場合は別のIDへの置換)、年齢、身長、体重などの準(間接)識別子は本人のアイデンティティを保護するために削除または不明瞭化、集約化などがされます。
非識別化を、直接的に識別可能な情報(氏名や電子メールアドレスなど)と本人との関係性を取り除くことと考えている組織もあるが、直接識別子と準識別子の両方を非識別化することで、非識別化の定義がより包括的になり、かつ実際に多くの組織の意見はその考えをもっているため実態に沿うことになると考えているようです。
仮名化(Pseudonymsation)の定義
日本の個人情報保護法でも令和4年4月1日から施行される改正法で「仮名加工情報」という定義が追加されましたが、PHUSEの仮名化の定義は以下の通りです。
なお、たまに「仮名」を「かな」と読んでいる人がいますが、この文脈での「仮名」は「かめい」と読みます。
A type of de-identification that both removes the association with a data subject and adds an association between a particular set of characteristics relating to the data subject and one or more pseudonyms. Typically, pseudonymisation is implemented by replacing direct identifiers (e.g. a name, a subject ID) with a randomly generated value.
Terminology Harmonisation in Data Sharing and Disclosure Terms and Definitions (version 2)
「データ主体(本人)との関連性を取り除き、データ主体に関連する特徴的な特性(情報)と一つ以上の仮名との関連性を加える非識別化の一種である。仮名化は、直接識別子(名前や被験者IDなど)をランダムに生み出した値に置き換えることで実施される。」といった感じでしょうか。
仮名化の定義は、匿名化や非識別化と異なり、調査に当たった際の情報ソースの間でそれほど大きな違いはなかったそうです。確かに仮名化は、医学研究の領域では世界的に同じルールで実施されてきましたし、加工自体がシンプルなので、定義がバラつくことは少なそうです。
ただ、「仮名はランダムに生み出したものでないといけない」となると、実態とは少し異なってくるかもしれません。被験者識別コードによる仮名も、外形的には仮名化の一種ですが、被験者識別コードは必ずしもランダム性はないかと思います。意図的に本人の識別性が残るような方法で仮名が割り当てられなければならないという意味でランダムとしていると思うのですが、その趣旨が踏まえられていれば、必ずしもランダムでいけない理由は少ないように、個人的には考えます。
匿名化(Anonymisation)の定義
PHUSEによる匿名化の定義は以下の通りです。
The overall process of protecting the privacy of data subjects, including clinical study participants, and reducing the risk of re-identification by 1) modifying (e.g. suppressing, obscuring, aggregating, altering) identifiable information in structured data and documents, 2) assessing and controlling the residual risk of re-identification and 3) considering the context of the data release.
Terminology Harmonisation in Data Sharing and Disclosure Terms and Definitions (version 2)
「1)構造化データや文書に含まれる識別可能な情報を修正(低減、不明瞭化、集約化、変更など)し、2)再識別の残存リスクを評価・管理し、3)データ公開の文脈を考慮することにより、臨床試験参加者を含むデータ対象者のプライバシーを保護し、再識別のリスクを低減するための総合的なプロセス。」といった感じで、匿名化だけClinical Trial Data Sharing(CTDS)を意識した定義になっているように感じます。
匿名化の方法(考え方)自体は、非識別化とあまり違いがないように感じますが、それはPHUSE自体もそう考えているようです。またここでいう「匿名」は絶対的なものではなく、また特定のプロセスを踏むことで得られるものではなく、データが公開される状況や再公開のリスクを考慮して匿名化したものが「匿名化されたデータ」「匿名化された文書」になる、という考え方のようです。
誤解を恐れずに言えば、利用する匿名化手法は匿名化でも非識別化であっても一緒だけど、匿名化という言葉には、「データの有効性を残すため一定の再識別リスクを許容しながら、データ公開されるコンテキストを踏まえた上で匿名化処理をしたもの」という意味が「非識別化」の意味に加えられているように理解しました。
まとめ
以上、PHUSEが整理した、匿名化、仮名化、非識別化の定義について見てきました。
最初に資料中にあるFigure 4の図を見たときには、なぜこのような整理になっているのか疑問に思いました。というのも、日本の個人情報保護法でも、EUのGDPRでも、匿名化と仮名化は別の概念であり、少なくとも包含関係にはありません。
しかし、上述のようなPHUSEの考え方に基づく用語の定義からすると、この図も理解できます。
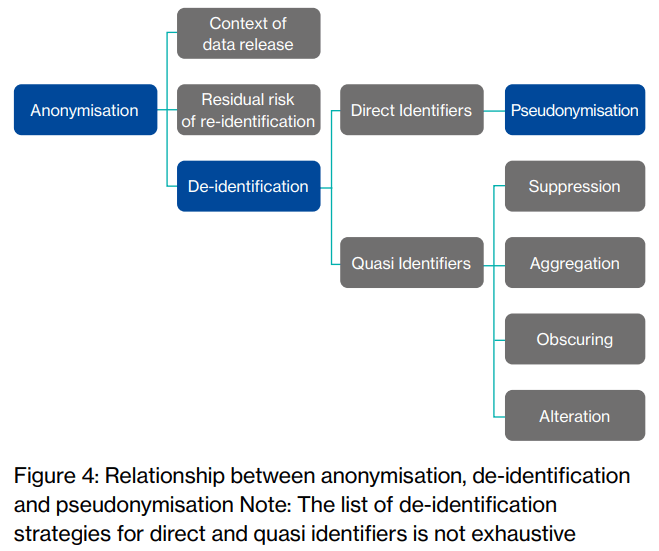
この定義は、あくまでPHUSEがCTDSの文脈で整理した用語の定義です。一般的な匿名化の定義とは異なることに注意が必要ですね。

