
2023年5月16日追記:
ここで取り上げた「Data Quality Framework for EU medicines regulation」につきまして、製薬協が翻訳し、2023年5月に下で公表されたのでご紹介します。

EMAは2022年10月10日に、「Data Quality Framework for EU medicines regulation」という文書を公表しました。
Data Quality Framework for EU medicines regulation
この文書は、医薬品規制においてベネフィット・リスクの決定を支援するために使用されるデータの質について、より一貫した標準的なアプローチをとるための基準を定めるための文書の案となっています(2022年11月18日までパブコメ受付中)。
この文書の作成では、TEHDASのWorking Package 6からの成果物6.1であるEuropean Health Data Space Data Quality Frameworkを参考に考えられています。
TEHDASのEuropean Health Data Space Data Quality Frameworkについては以下でご紹介しております。

今回のEMAにおける「データの質」の定義も、TEHDASで提案された定義がそのまま使用されています。
データの質とは、ヘルスリサーチ、政策決定、規制に関する利用者のニーズに対して目的に適合しており、データが表現しようとする現実を反映していること
また、データ互換性はデータの質の評価に重要な機能ではないとみなされている点など、基本的にはTEHDASの考え方を踏襲しています。
一方で、TEHDASにおいて評価指標の一つの次元とされていた一貫性(Coherence)と網羅性(Coverage)が、この文書ではExtensivenessという言葉で集約されているなどの違いがみられるところもあります。
この「Extensiveness」という言葉を表現する日本語を見出すことができず、仕方がなく、以降では原文通り「Extensiveness」という表記を用いております。
しっかり読み込まないと難しい内容だと思いますので、ドラフトではありますが、興味のある方は是非、原文をご確認ください。
なお、この文書で説明されているデータの質に関するフレームワークは、医療データ/RWDに限らず、医薬品の評価やモニタリングの文脈で、データ解析により得られたエビデンスに基づく規制当局による意思決定の場面で広く適用されることが意図されており、その対象としては、オミックス分析、前臨床、副作用自発報告、化学・製造管理データなど、幅広いデータで適用できるものとして考えられていますので、今後の展開にも注目です。
RWDのデータの質に関する入門書は、2015年に製薬協が公表したこちらの文書が分かりやすく参考になると思います(医事会計、DPCなどの制度的な変化についてはご注意を)。

- 1. エグゼクティブサマリー
- 2. 用語集
- 3. 背景 – 医薬品規制のためのデータ品質フレームワークの必要性
- 4. 本データ品質フレームワークの適用範囲
- 5. データ品質の維持及び評価の基礎となる一般的な考慮事項
- 6. DQの次元と評価指標
- 7. 一般的な推奨事項と成熟度モデル
- 8. 意思決定のためのデータの規制的利用
- 9. 参考文献
1. エグゼクティブサマリー
HMA-EMA Joint Big Data Task Force (BDTF) の勧告および HMA-EMA Joint Big Data Steering Group (BDSG) のワークプランで認められているように、データの品質と代表性のための EU フレームワークを確立することは、(ビッグ)データの可能性を十分に実現し、規制上の決定を促進するために重要な要素である。
本書は、医薬品規制のためのEUデータ品質フレームワークの最初のリリースであり、欧州医薬品規制ネットワーク(EMRN)の規制活動全体に適用される高レベルの原則と手順を取り上げている。このフレームワークは、規制当局の意思決定に関連するデータ品質に関する一般的な考察、データの次元及び下位次元の定義、それらの特性及び関連する評価指標を提供するものである。また、様々なシナリオにおいて、どのようなデータ品質のアクションと評価指標を導入することができるかを分析し、データ駆動型の規制上の意思決定を支援するための自動化の進化を促進する成熟度モデルを導入している。
この文書は、特定の規制領域に対して、特定の評価指標やチェックを用いて、より焦点を絞った推奨事項を導き出すことができる包括的な考え方(an overall umbrella)となることを意図している。
2. 用語集
| CDM | Common Data Model |
| DQ | Data Quality |
| DQF | Data Quality Framework |
| EHR | Electronic Health Record |
| EHDS | European Health Data Space |
| EMA | European Medicines Agency |
| ETL | Extract, Transform and Load |
| FAIR | Findable, Accessible, Interoperable and Reusable |
| GxP | Good x Practices (where x stands for the type) – Good Laboratory Practice (GLP), Good Clinical Practice (GCP), Good Manufacturing Practice (GMP), Good Distribution/Documentation Practice (GDP) |
| ISO | International Organisation for Standardisation |
| SQuaRE | Systems and software Quality Requirements and Evaluation |
| QMS | Quality Management System |
| QSR | Quality System Regulation |
3. 背景 – 医薬品規制のためのデータ品質フレームワークの必要性
HMA-EMA合同ビッグデータタスクフォース(BDTF)の勧告やHMA-EMA合同ビッグデータ運営グループ (BDSG)の作業計画で認められているように、データ品質(DQ)と代表性のためのEUフレームワークを確立することは、(ビッグ)データの可能性を最大限に実現し規制決定を促進するために不可欠な要素である。
近年、EUの規制評価プロセスは、主に文書ベースの提出から、それらの文書の作成に使用した基礎データの直接評価へと徐々に移行している。このプロセスの変化は、DQを特徴付け、データが意思決定の目的に適合しているかどうかを規制当局が信頼できる形で評価できるようなフレームワークの必要性をもたらしている。
さらに、デジタル化・情報化の進展とそれに伴う膨大なデータは、機会を創出する一方で、規制当局の意思決定がますます複雑化する要因にもなっている。新しいタイプのデータが利用可能になるにつれ、そうしたデータが規制上の意思決定に適切であるかどうかを示すガイドラインや方法はまだ生まれていない。そのため、一貫した品質評価手順を導くための DQF が必要とされている。
顕著な例として、医薬品の規制上の意思決定を支援するために利用可能な医療データが増加していることが挙げられる。臨床試験は依然として承認前の段階で医薬品の安全性と有効性を確立するための基本的な方法であるが、現実の世界を完全に反映しているわけではない。その結果、規制当局の申請書類と、HTA、支払者、最終的には臨床医や患者などの下流関係者が必要とするその後の臨床的エビデンスとの間にギャップが生じている。欧州医薬品審査庁(EMRN)が受け取ったデータは、これらのギャップを埋める可能性を秘めているが、その可能性を実現するために、欧州医薬品審査庁(EMRN)は、これらのデータがどの程度正確で目的に合っているかを記述し定量化する能力を獲得する必要がある。
4. 本データ品質フレームワークの適用範囲
本DQFの適用範囲は、規制当局による意思決定のためのデータ品質の特性化及び評価を目的として、広範なデータ源に首尾一貫して適用できる一連の定義、原則及びガイドラインを提供することである。
データの種類や情報源によって方法、用語、評価指標、問題点が異なるため、このフレームワークは、現在及び新規のデータ種類に対するDQ評価手順及び勧告を特定、定義、さらに開発するための一貫で包括的な考え方(coherent umbrella)を提供することを目的としている。
したがって、このフレームワークの目的は、DQ 関連プロセスの一貫性を実現し、DQ のための水平システムの開発を可能にし、最終的には規制上の意思決定におけるデータのより直接的かつ自動的な利用を可能にすることである。
このフレームワークはTEHDAS[1]の勧告を基礎とし、品質の次元及び評価基準の分類並びにそれらの適用のためのガイドラインによって拡張されたものである。特に、[1], [2], [3], [4], [5], [6], [7], [8], [9], [10] など、125のDQフレームワークで提案されている定義と勧告を基にしている。
4.1. データ品質の定義
一般に、品質とは、製品又はサービスが法的及び規制上の要件の範囲内で顧客及びその他の利害関係者のニーズをどの程度満たしているか、又は意図された使用に対する適合性を定義する属性と定義される[2]。データにも同じ原則が適用され、この文書の目的上、我々は次の定義を採用する。
「データの質とは、ヘルスリサーチ、政策決定、規制に関する利用者のニーズに対して目的に適合しており、データが表現しようとする現実を反映していること」、と定義される[1]。
したがって、本DQFでは、規制上の意思決定に関連するDQの側面にその範囲を限定している。
4.2. 適用範囲の制限
DQの定義及び規制上の意思決定という限定的な焦点に従って、本フレームワークの適用範囲には以下を含めない。
– 基礎となるデータからの洞察または結論を意図して生成されたエビデンス。本フレームワークは、規制当局の意思決定に用いられるデータの品質レベルを評価するためのガイドラインを定義することに主眼を置いており、規制当局の意思決定におけるデータの実際の利用やその方法には関係していない。
- 規制当局の意思決定に直接影響を与えない DQ に関する観点(例:簡潔性、アクセシビリティ)。
- データが参照する基礎的要素の品質。例えば、医薬品の純度に関するデータセットを検討する場合、このフレームワークはデータの信頼性、完全性、その他の側面を対象とするが、医薬品そのものの品質(この場合は純度)についての側面は対象としない。
- 意味的な相互互換性(Semantic Interoperability)と標準化。これらの側面はデータの使いやすさやDQの評価にとって重要であるが、品質そのものの評価には関係しない。規制当局の質問に答えるという点で目的に適っていないデータは、標準化しても適うようにはならない。標準化されていないデータであっても、理論的には規制当局の質問に答えるために使用することができ、DQFも理論的には個々の標準化されていないデータ源に適用することができる。したがって、相互運用性のための標準を定義し、選択するためのガイドラインや勧告の提供は、本 DQF の範囲外であると考えられる。複数のデータソースにまたがる品質の評価に影響を与える場合には、標準の適用を要求することは本書の範囲内に含まれる。
同様に、DQを保証するためのシステム、プロセス、責任の具体的な設計について勧告を行うことは本ガイドラインの範囲ではないし、特定のソリューションや製品を列挙することも適切ではない。しかし、DQの側面に関するエビデンスを提供するためのそれらの要件は範囲内である。
このフレームワークは、医療データの作成及び管理に関して設定された他のガイドラインを補完し、規制活動における利用を可能にし、最適化することを意図している。
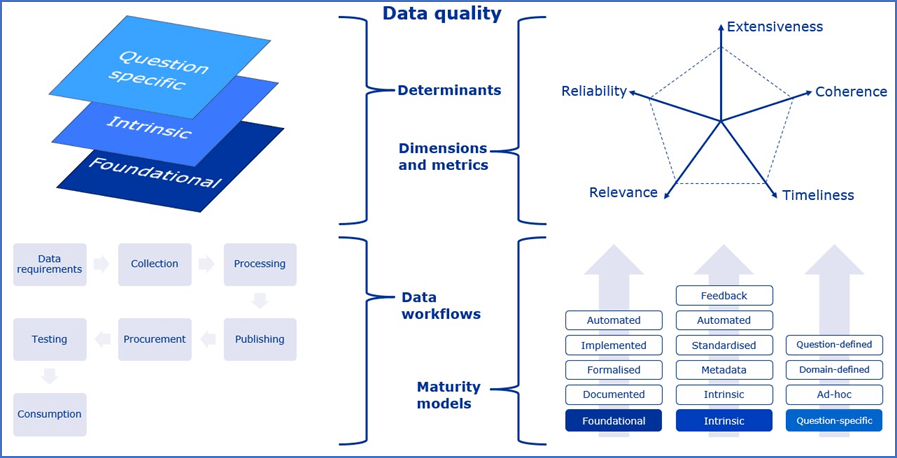
4.3. 本DQFの構造
EU 医薬品規制のための DQF は、規格化プロセスの異なる段階を反映し、2つの部分から構成されている。
最初のパート(一般的なフレームワーク)では、広範なデータタイプを包含し、新規のユースケースに拡張可能なDQの一貫したアプローチを提供するために設計されている。これを達成するために、異なるデータの種類やシナリオに適用される様々なDQの観点について共通の基盤を提供する。また、DQの定義、DQの次元、およびその次元をカバーする評価指標の例を示す。さらに、DQプロセスの適用に関する一般的なパターンを特定し、データ駆動型の医薬品規制意思決定の自動化を促進するために設計された一連の成熟度モデルを明確にするものである。
2つ目のパート(フレームワークの特化)では、特定のデータタイプや規制上の疑問に対応するために、このような一般的な推奨事項に特化し、最終的には拡張する。このパートは、実際に実施可能なガイドラインを作成するための基礎となるものであり、データや技術の変化に応じて進化していく必要がある。
本書は欧州医薬品規制ネットワーク(EMRN)[11]のためのDQFの第一版であり、公開協議のために発表された。本書は一般的なフレームワークに焦点を当て、医薬品規制の文脈におけるDQに関する一般的なフレームワーク、用語、定義、一般的な指導原則を扱っている。
今後数年間、DQFは毎年更新され、特に関心のある規制上のユースケースをさらに深く掘り下げていく予定である。この文書は、TEHDASの開発に合わせて、欧州医薬品規制ネットワーク(EMRN)のデータ承認プロセスおよびEHDSとの連携をさらに強化する予定である。
5. データ品質の維持及び評価の基礎となる一般的な考慮事項
5.1. エビデンス生成のためのデータ品質決定要因
規制目的で使用できるデータには多様なデータソースがあり、それぞれは異なるプロセスで生成され、異なる主要な用途に適合している。規制当局の意思決定の時点でデータセットの全体的な質を考慮する場合、何が質に寄与し、何がどの段階で測定または管理できるかを区別することが重要である。このフレームワークでは、DQに関連する要素(ここでは「決定因子」と呼ぶ)を3つのカテゴリーに分類している。
基本的決定要因とは、データが生成され、収集され、利用可能になるまでのプロセスおよびシステムに関するものである。基本的決定要因とは、データの品質に影響を与えるものであるが、データ自体の一部ではない(従って、データセットの内容には依存せず、データセットから導き出すこともできない)。規制当局の意思決定においてデータが信頼されるためには、データを収集し、保存し、移動させる基礎となるインフラが、「データ」と「データが表現する現実の実体」との対応関係が変化しないように設計されていることを評価する必要がある。
データ固有の決定要因とは、特定のデータセットに固有の側面に関するものである。本質的な決定要因は、データセットと、場合によっては何らかの外部の一般的な知識が与えられた場合に導出できるものであるが、データが生成されたコンテキストや、データが使用されるコンテキスト (科学的または規制上の問題など) に関する知識はない。
質問特有の決定因子は、一般に特定の質問から独立して定義することができないDQの側面に関係する。
一般に、基本的決定要因はDQに直接的な影響を与える。これらをコントロールできない場合、DQ固有の側面をコントロールすることが唯一の選択肢となる。質問(または典型的な質問のセット)が定義されていない場合、そのようなコントロールの範囲は制限される。
5.2. エビデンス生成過程(データライフサイクル)に沿ったデータ品質
エビデンス生成に利用可能なデータは、データの種類、それを生成する大規模なプロセスや組織に特有のプロセス(より広範な「ライフサイクル」2 の一部)を経ている。
参考までに、一般的な高レベルのライフサイクルの概要を以下に示す。
- データ要件の定義
- データの収集または生成
- データの管理および処理
- データの公開
- データの調達と集約
- テストと受入れ
- 消費のための引渡し
全てのデータワークフローに全ての段階が存在するわけではなく(例えば、センサーやソーシャルデータから収集されたデータは、特定の要件に基づくのではなく、「利用可能なもの」ベースで収集されるかもしれない)、場合によっては余分な段階が適用されるかもしれない。
DQの管理及び評価の範囲については、このプロセスのどの段階でどのような決定要因が適用され、どのような影響を及ぼすかを評価することが重要である。例えば、DQに固有の観点が評価されうる。このような評価は、データの収集および生成の段階で信頼性を向上させるために用いられるかもしれないし、発行時に品質の評価を提供するために用いられるかもしれないし、データを追加データと統合するたびには再評価されるに違いない。5.2.1.質問特有のDQの決定要因は、本来収集されなかった質問に答えるためにデータが再利用されるたびに再評価される必要がある。
5.2.1. データの一次利用 vs 二次利用
ガイドラインと評価指標(metrics)を適用する際、データの一次利用と二次利用の間に重要な区別が生じる。システムが特定の一次目的のためにデータを収集し処理するように設計されている場合、または二次利用のために確立された一連の要件が存在する場合、固有的かつ質問特有的なDQの側面は、収集および生成の時点で すでに考慮されている可能性がある。したがって、エビデンス生成に必要となる、ある程度の品質レベルを保証するシステムおよびプロセスを設計することが可能である。しかし、想定していなかったデータの二次利用の場合はそうはいかない。二次利用のための品質基準は、既存のデータ収集の目的に関連した基準とは一致しないことがある。この場合、ほとんどのDQは事後的にしか管理できない。
5.2.2. 発行(Publication)とデータ消費(Data Consumption)
データのライフサイクルに沿って、データは2つの異なるコンテクストを通じて処理される。一方(発行)では、データは生成または収集され、処理され、利用可能にされる。もう一方(消費)では、データを調達され、分析をサポートするために集約される。この2つのコンテキストは、オーバーラップしている場合(例えば、結果を検証するために直接測定する場合)もあれば、非常に異なる場合(例えば、想定されるまたは想定されない使用方法の範囲のためにデータを収集しカタログで公表する場合)もある。品質評価の包括的な目的はこの2つの文脈で変化し、同じデータセットでも品質の本質的な側面は異なる場合がある。例えば、データカタログの場合は、一般的な利用方法に対して許容できる最低限の品質、データ調達の場合は、特定の質問に対する最低限の実行可能性というように、品質評価の詳細な仕様は、これらの文脈に応じて個別に策定されるかもしれない。
5.3. データとメタデータ
メタデータは伝統的に「データに関するデータ」と定義され、データの目的や生成に関する文脈を提供する。データが数値や非構造化情報(例:画像)からなる場合、メタデータは通常データセットに追加して提供される(例:ファイルやカタログの項目で)。一般に、データとメタデータの区別は十分に定義されていない。ある状況(例えば、ある検査のための装置提供者)においてメタデータとして現れるいくつかの情報は、別の状況(例えば、測定バイアスの評価の場合)においてはデータとみなされることがありうる。
規制当局の意思決定においては、メタデータは一般的にデータと同じフレームワークに従う必要がある。より正確には、メタデータに何らかの変更があった場合、下流で作成されたエビデンスの改訂が必要となるなら、それはDQの観点からはデータとして扱われるべきである。
DQの観点からは、メタデータはデータセットの評価指標(metrics)および要約記述に限定されるものではな く、情報源、プロセス、およびデータ要素の定義の特徴にまで拡大されるべきものと考えるべきである。
5.4. リファレンスのフレーム(妥当性確認と検証)
DQのいくつかの側面は異なる基準から評価されうる。すなわち、データセット内に存在するもの(情報)、あるいはデータセットの外部に存在するもの(実世界にも広がりうる)という基準がある。例えば、動物の体重は、データセットの内容(例えば欠損値)に基づいて、全体的な基準又はゴールドスタンダード(例えば自然な体重範囲に関する知識)に基づいて、あるいは現実に即して検証することが可能である。
いくつかのフレームワークでは、データセット内の品質の評価は「検証(verification)」と呼ばれ、ゴールドスタンダードに関する評価は「妥当性確認(validation)」と呼ばれる(この妥当性確認の概念は、一貫性チェックの一形態としての妥当性確認と混同されるべきではない)。
5.5. データおよびDQの粒度
DQは異なる粒度で評価することができる。
- 値レベルは、特定のデータポイント(例えば、重量)に対応する。
- 列レベル(「変数レベル」とも呼ばれる)は、個人のサンプル全体のデータポイントを対象とする(例:臨床試験のDMテーブルの変数としての体重)。値レベルのDQの指標は、例えばバイナリ値をパーセンテージに変換することにより、容易に列レベルに拡張することができる。
- データセット・レベルは、オブザベーションの全体集合をカバーする。ある文脈では、データセット内で、類似のエンティティに関するデータセットの部分の間でさらに区別することができる。このような区別がある場合、そのような部分を「表レベル」と呼ぶ(これらの部分は通常、 別々の表で表示されるからである)。
このDQFでは、可能な限り低いレベル、すなわち、値レベルに焦点を当てる。しかし、評価指標によっては、より高いレベルの品質次元にしか適用できないものもある。例えば、体重が 300 kg の人の1 つのレコードの妥当性は単位(基準)違反にならないかもしれませんが、80% のレコードが 300 kg を超えている場合は違反になりえる。
6. DQの次元と評価指標
DQ の次元と評価指標の定義は、次元、評価指標、および測定値の一般的な定義に依存している。
- 次元(dimension)は、現実の 1 つまたは複数の関連する側面や特徴を表す(例:物理的対象物の長さ)。
- 評価指標(metric)は、次元の値を評価する方法を表す(例えば、ある特定の状況下においてメートル単位で測定された絶対的な長さなど)。
- 測定値(measure)は、1 つのデータ・ポイント (例: 2cm) を表す。より多くの測定値を組み合わせて、より一般的な測定値(例えば、平均長)を導き出すことができる。
DQの評価指標は、1 つ以上の品質次元の評価を導き出すためにデータソースに適用できる指標として定義できる(以下の一貫性の例の説明のように、1 つの品質評価指標を複数の次元の指標として使用することができる)。いくつかの評価指標については、一次利用を目的にデータが収集されたとき、または十分に定義された二次利用が設定されたときに、受け入れを許容する閾値を定義することがある。このような閾値は、データ収集の時点で定義することができる。そして一般的には、予期しない二次利用に対して、閾値は疑問(または包括的な一連の疑問)に応じて定義されうる。
データの質は、データの表現だけでなく、現実との対応関係など、データのいくつかの特徴の総和である。このような特徴を次元、つまりDQの独立した側面を明らかにする特徴の集合に分類することは有用である。言い換えれば、異なる次元は異なる明確なDQに関する疑問に答える。
いくつかのデータフレームワークは、DQを次元で整理することを提案しており、それらはフレームワーク間で類似しているが、しばしば正確な定義に一貫性がない。このため、複数のソースを集計した場合、DQの一貫した評価が難しくなる。ここでは、規制の観点から関連する一連の次元を紹介し、正確な定義、可能な評価指標、および例を挙げて補足する。その目的は、曖昧さを取り除き、様々な情報源から得られる異なる品質の概念を、エビデンス生成を支援するための評価指標や成熟度モデルを構成するのに有効な共通項の対応付けに役立つリファレンスを提供することにある。
6.1. 信頼性(Reliability)
我々は信頼性を、データが測定するために設計されたものをどれだけ忠実に反映しているかをカバーする次元と定義している(この「信頼性(Reliability)」の概念は、DQFではしばしば「正確性(Accuracy)」または「もっともらしさ(Plausibility)」と呼ばれている。)。
信頼性(Reliability)の次元は、「データはどの程度まで現実に即しているか」という問いに答えるものである。
品質の「目的適合性(fit for purpose)」の定義を考えるとき、信頼性(Reliability)とはデータがどれだけ正しく、信頼に足るものであるかということである。
6.1.1. 信頼性(Reliability)の下位次元
信頼性(Reliability)の定義に基づき、他の次元を下位次元として関連付けることができる。
- 精度(Precision)は、データが現実を表現する際の近似度として定義される。例えば、ある人の年齢を年または月で報告することができる。
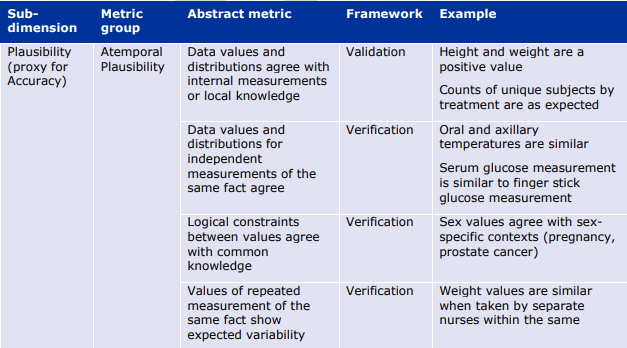
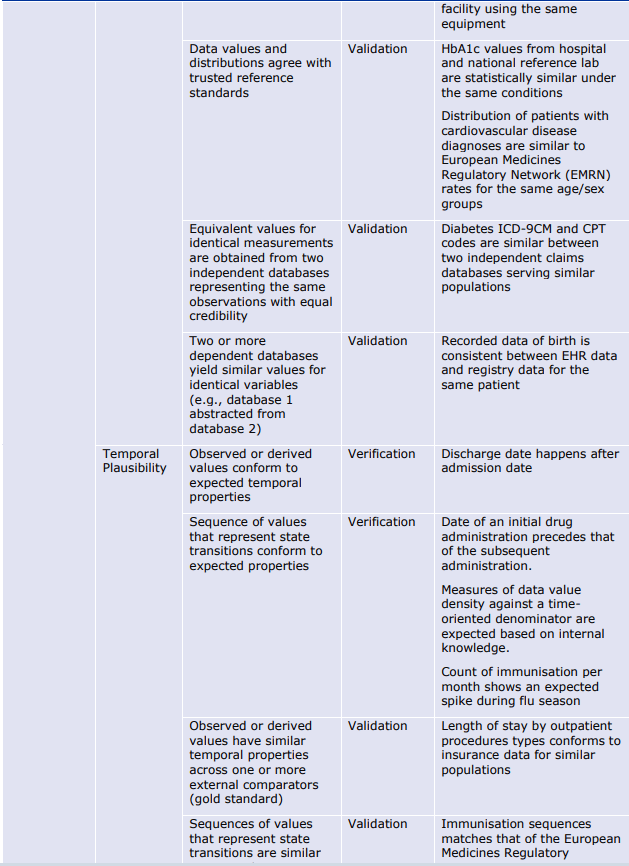
- 正確性(Accuracy)は、データと現実の間の不一致の度合いとして定義される。これは、測定における正確さの正式な定義(例えば、測定値と実際の値との距離)と、データセット内の誤った情報の量の測定値を含むものである。例えば、人の体重は、完全に服を着た状態で測定した場合、1~2kgの系統的な過重が与えられる可能性がある。
- もっともらしさ(Plausibility)は、データ項目が表現しようとする実体と対峙することでしか測定できないため、データ指向の枠組みでは測定が難しい。ある情報が真実である可能性として定義される「確からしさ」は、エラーを検出するための代用品である。ある情報の組み合わせが現実世界では起こりそうにない(あるいはあり得ない)場合、これは正確さの問題を明らかにする。 例えば、ある人の体重が300kgを超えることはあり得るが、データセット中の多くの、あるいはすべての人の体重がその値を超えることはあり得ず、測定やデータ処理に何らかの誤りがあることが明らかになる可能性がある。
6.1.2. 信頼性(Reliability)の決定要因
信頼性(Reliability)は基本的に、データの一次収集と処理の場におけるシステムとプロセスに依存する。エラーがなければ、データ集計の過程で精度が低下することはない。むしろ、データが共通のモデルに整合化されたときに精度が低下する可能性がある。信頼性(Reliability)の本質的な側面は、純粋なデータ指向のフレームワークで測定することは困難だが、もっともらしさの測定は、ある種のエラーを検出する方法を提供することがある。各疑問がデータとの関連において、許容できる信頼性の閾値を決めるが、信頼性(Reliability)は特定の問いからは独立したものである。
6.1.3. 信頼性(Reliability)の評価指標

6.2. Extensiveness(Completeness and Coverage:完全性と網羅性)
完全性(Completeness)と網羅性(Coverage)はDQFに見られる2つの典型的な次元であり、利用可能なデータ量に関連する包括的なカテゴリー(Extensiveness)として統合している。
「Extensiveness」は、「どれだけのデータを保有しているか?」という問いに答えるものである。品質の目的適合性(fit for purpose)の定義を考えると、「Extensiveness」は「データがどの程度十分か?」という情報を含んでいる。
6.2.1. Extensivenessの下位次元
利用可能な情報量を考える場合、利用可能な情報全体に対する割合で表現することが考えられる。完全性(Completeness)と網羅性(Coverage)の区別は、完全に利用可能な情報のスコープの定義に起因する。
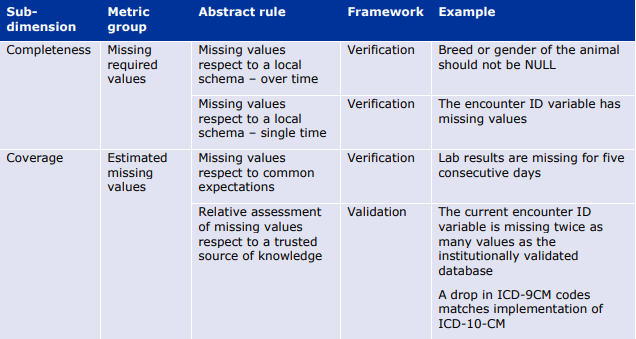
- 完全性(Completeness)とは、データ収集のプロセスとデータ形式を考慮した上で、利用可能な情報の総量に対する利用可能な情報の量を測定するものである。データセットで利用できないデータは「欠損」と呼ばれる。例えば、あるデータセットにおける必須項目(性別など)の値が欠落している割合が、完全性を測る指標となる。
- 網羅性(Coverage)は、現実世界に存在するものに関して、それが収集過程やデータフォーマットの内部にあるかどうかにかかわらず、利用可能な情報量を測定します。情報の総量が定義できない、あるいはアクセスできない可能性があるため、カバレッジは簡単に測定することはできない。網羅性の問題の例としては、データセットに存在する個人の集合が、調査対象の集団を代表しているかどうかが挙げられる。
完全性(Completeness)と網羅性(Coverage)に関連する概念として、データセットのカバー率に対する不完全なデータの影響を特徴付けることを目的とした「欠損」がある。
6.2.2. Extensivenessの決定要因
収集された情報のExtensivenessは、データ収集プロセスの仕様に依存する。しかし、二次利用のために異なるデータセットを統合する場合、全体のデータセットの完全性については保証されない。データ固有レベルでは、データの完全性のレベルを評価する指標に頼ることができる。あるデータモデルに含まれる可能性のあるデータに対して、データセットに含まれるデータの量を評価する指標は、計算が簡単で効果的である。測定しようとする母集団に対してデータがどれだけ完全であるかを評価する指標はより複雑で、ゴールドスタンダードと対立する可能性がある。スキーマに対する完全性は簡単に定義できるが、網羅性は研究時にのみ定義されうるいくつかの仮定に依存する。研究時に、私たちは通常、意図している研究課題に対して許容できる閾値(90%の完全性)を定義することになる。
6.2.3. Extensivenessの評価指標
6.3. 一貫性(Coherence)
我々は「一貫性(Coherence)」を,データセット全体のさまざまな部分の表現と意味がどのくらい一貫しているかを表す次元として定義している。
一貫性(Coherence)とは、「データセットが “全体 “として処理可能か」という問いに答えるものである。値の形式(例:日付)はデータセット全体で同じか?値の精度は同じか(例えば、年齢は常に年単位で近似される)?実体の参照は一貫しており、同じ実体に関する情報がデータセットの各部分間で適切に「リンク」されているか?品質の目的適合性(fit for purpose)の定義を考えるとき、一貫性(Coherence)はデータの分析可能性に関係する。
6.3.1. 一貫性(Coherence)の下位次元
一貫性(Coherence)は、consistencyとvalidationに密接に関連するニュアンスのある次元である。consistencyとCoherenceはほぼ同義語と考えることができる。ただし、不一致性の検出はデータの信頼性を測定する方法であることが多いという注意点がある。
ここでは、一貫性(Coherence)の下位次元として以下のものを考えている。
形式的一貫性(Format Coherence):データセット全体でデータが同じ方法で表現されているかどうか(例えば、DD-MM-YYYYとMM-DD-YYYYで表現された日付が混在するデータは、統合分析には適さない)。
構造的一貫性(Structural Coherence):データセット全体を通して、同じエンティティが同じ方法で識別されているかどうか。構造的一貫性の下位側面は、参照が正しいエンティティに解決されることである。
意味的一貫性(Semantic Coherence):データセット全体を通して、同じ値が同じことを意味するかどうか。例えば、「無尿」は尿の生成が完全に停止している状態を意味するのか、それとも尿の量の測定値を意味するのか、あるいは、同じ測定値の概念がデータセット全体で同じ精度を持つことを意図しているのかどうか。
一意性(Uniqueness):本フレームワークの範囲では、一意性(Uniqueness)を一貫性(Coherence)の下位次元と考える。一意性(Uniqueness)とは、同じ情報が重複することなく、データセットに一度だけ現れるという性質である。この問題は、異なるソースからのリンクデータで典型的なものである。
一貫性(Coherence)に厳密に関連するのは、適合性(Conformance)と妥当性(Validity)である。
適合性(Conformance)は、特定の参照やデータモデルに対する一貫性(Coherence)を評価するという点で関連する。適合性(Conformance)は、実質的に一貫性(Coherence)を評価する最良の方法であり、形式的・構造的・意味的な適合性(Conformance)として専門化されています。妥当性(Validity)は、より狭い範囲の適合性(conformance)であり、参照モデルが評価対象のデータセットに固有のものである場合に定義される。
6.3.2. 一貫性(Coherence)の決定要因
ソースデータの一貫性(Coherence)は、データを生成する組織全体のプロセスとシステムの同期、または複数のデータを集約する場合は、その組織が内部または外部のデータ標準の使用を約束するかどうかに大きく依存する。さらに、集約されたデータを二次利用する場合の一貫性(Coherence)は、共有された標準と参照データを利用できるかどうかによって決まる。データセットに内在する一貫性(Coherence)は、主にデータ処理の過程で改善することができる。しかし、一貫性(Coherence)の向上がデータの意味の近似や明確化を伴う場合、しばしばソースシステムやプロセスへのアクセスが必要になる(例:明確化のため)。意味的な一貫性には、指標で評価することが難しく、クエリ時にしか比較できないものもある。
6.3.3. 一貫性(Coherence)の評価指標
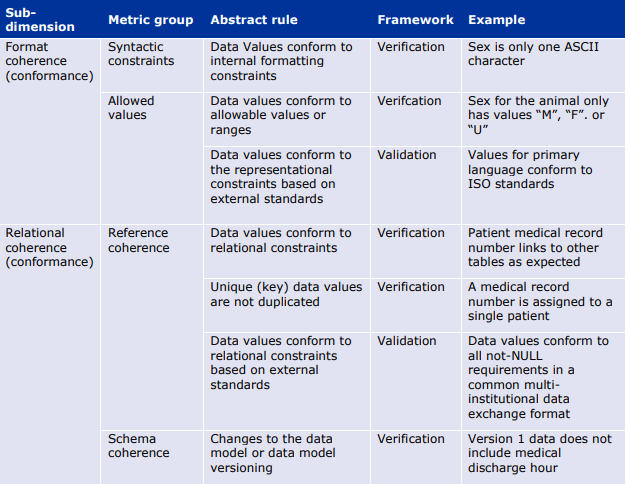
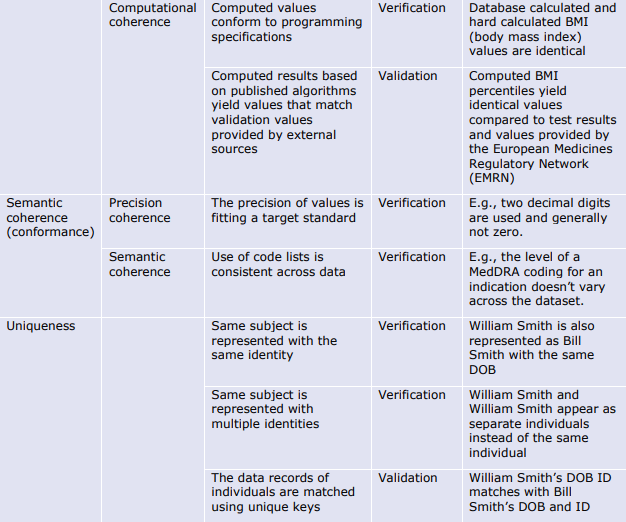
6.4. 適時性(Timeliness)
我々は適時性(Timeliness)を、規制当局の意思決定において適切な時期のデータを入手できることと定義しており、そのためには、許容される時間内にデータが収集され、利用可能となることが必要である。
適時性(Timeliness)の次元は、「このデータは希望する時点の現実を反映しているか」という問いに答えるものである。
品質の目的適合性(fit for purpose)の定義を考慮すれば、適時性(Timeliness)には、データが測定しようとする時点の現実をどれだけ忠実に反映しているかが含まれる。
6.4.1. 適時性(Timeliness)の下位次元
最新性(Currency)は、データがどれだけ新しいか(例:最新ですぐに使えるか)を考慮する適時性特有の側面である。
我々のフレームワークの文脈では、データが予想より遅れて取得される側面として意図される「遅延性(lateness)」は、信頼性(reliability)の次元に該当する(このデータは現実に対応しているか)。
6.4.2. 適時性(Timeliness)の決定要因
適時性(Timeliness)は、データを収集し利用可能にするために使用されるシステムとプロセスによって決定される。
6.4.3. 適時性(Timeliness)の評価指標

6.5. 関連性(Relevance)
関連性(Relevance)とは,あるデータセットが,リサーチクエスチョンの答えに有用なデータ要素をどの程度含んでいるかということである。関連性(Relevance)という広い概念は、品質のあらゆる側面を含むが、ここでは、どのようなデータ要素が存在するかという狭い側面に焦点を当てる。
関連性(Relevance)の次元は、「そのデータセットは、特定の疑問に取り組むために必要な種類の値を示しているか」という問いに答えるものである。
品質の目的適合性(fit for purpose)の定義を考えるとき、(Relevance)とは、私たちが測定しようとする現実の側面をデータがどれだけ忠実に反映しているかということを意味する。
6.5.1. 関連性(Relevance)の決定要因
関連性(Relevance)は、規制上の問いとの関連においてのみ確立することができる。場合によっては、ある種のデータの用途の必要性を網羅する一連の典型的な問いを特定することが可能である。そのため、我々はそのような問いに関する関連性(Relevance)、つまり、あるドメインに関する関連性を確立することができる。
6.5.2. 関連性の評価指標

7. 一般的な推奨事項と成熟度モデル
規制当局の意思決定に使用するデータ資産を選択するには、その資産が信頼性(Reliability)、Extensiveness、網羅性(Coverage)、一貫性(Coherence)、 関連性(Relevance)の基準をどの程度満たしているかを知ることが最終的に必要である。このような品質の次元は、生成から処理、集計、最終的な分析に至るライフサイクル全体に沿って構築され、その過程で、もともと他の用途のために集められたデータを再利用することができる(倫理的または法的要件が満たされている場合[12])。
品質測定とチェックの方法は、データの種類とその使用目的によって大きく異なる。しかし、そのような測定やチェックを一貫した構造に従って整理することは可能であり、同質性の達成やギャップの特定に役立つ。
以下の表は、データとメタデータの両方について、品質の決定要因(基本的、データ固有、または質問固有)が異なる品質次元にどのように影響するかを例示したものである。これらの表は、データライフサイクルのどの段階でどのような評価指標や措置が適用されるかのガイダンスを提供する。例えば、Extensivenessの次元は、基礎的な決定要因のみによって決定される(例えば、製造時)。さらにデータのライフサイクルの中で、データ固有の指標は信頼性(reliability)の程度を部分的にしか評価できない(plausibility metrics:「もっともらしさ」の評価指標)。
これらの表は、規制目的のために DQ を特徴付けるための成熟度モデルの開発の基礎となるものである。成熟度モデルは、規制当局の意思決定を支援するために、最も効率的な方法で生成された最も強力な強力なエビデンスに向かって進歩するにつれて、成熟度の連続したレベルで決定要因をどのように特徴付けることができるかについてのガイダンスを提供する。
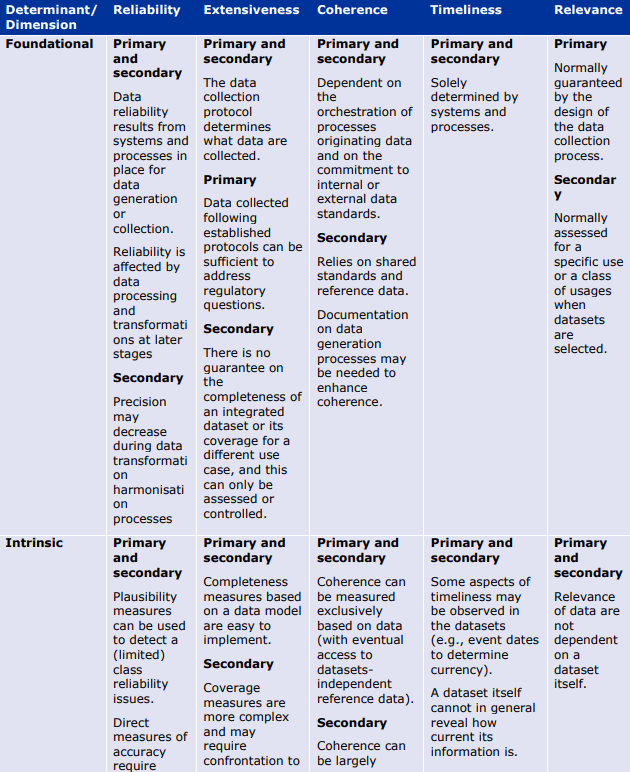
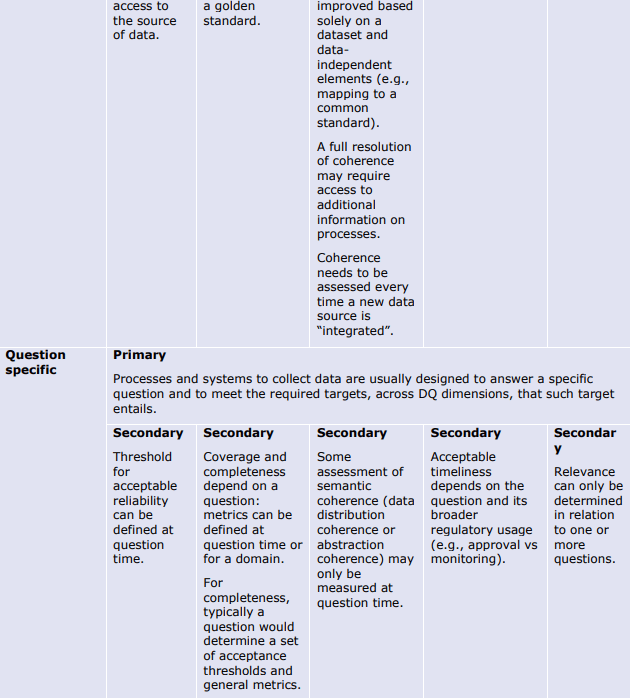
品質次元への決定要因-データ。
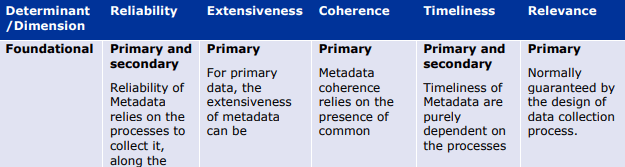
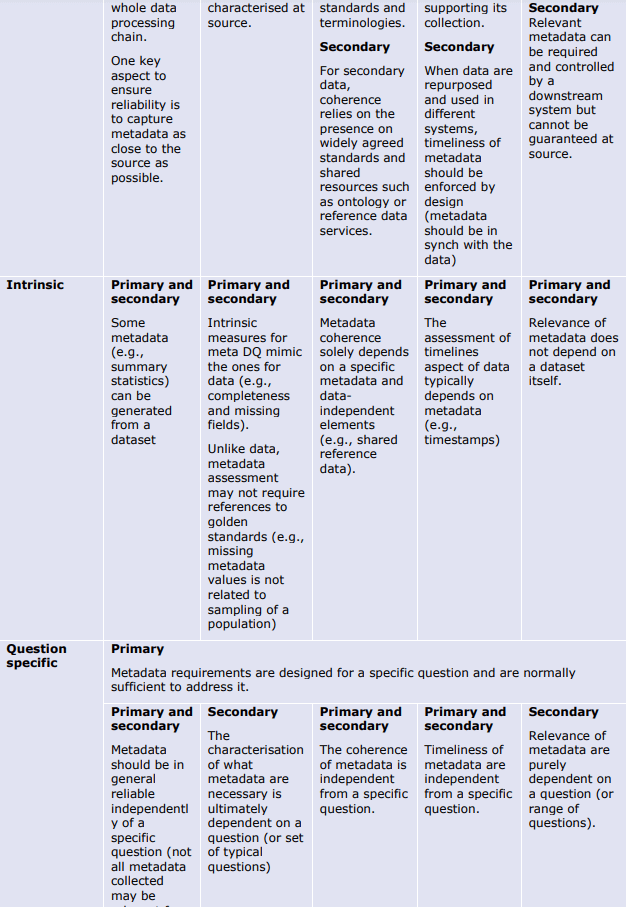

品質次元の意味合いへの決定要因-メタデータ。
7.1. 基礎的な決定要因:推奨事項と成熟度レベル
データの生成と処理の基盤となるシステムとプロセス(基本的決定要因)の特性は、DQを評価するために必要である。ここでは、一連の成熟度レベルを提供し、それぞれが基本的決定要因を特徴付けるための漸進的な推奨事項を提供し、大規模なエビデンス評価に支えられた改善の方向性を示すことを意図している。
7.1.1. レベル1:文書化されている
データを規制当局の意思決定に用いるためには、少なくとも、データの作成及び処理に関 するプロセスが文書化され、真実かつ検証可能でなければならない(関連する場合には、こ れはトレーニング手順にまで及ぶことがある)。これは、派生する情報及び文書の信頼性を確保するための基本であり、信頼性(Reliability)(精度:Precision)、Extensiveness,、一貫性(Coherence)、及び(関連する場合)適時性(Timeliness)の決定要因を網羅すべきである(これらの一部は特定の問いに依存するが、データ収集プロセス及びシステムは、通常、いくつかの主要な問いを基準として設計されるだろう)。データ処理と変換のための文書の提供もまた、信頼性の維持を保証するために不可欠であり、データのライフサイクルに沿った様々な関係者によるそのような処理のすべてについて提供されなければならない。
メタデータの観点からは、メタデータが参照するデータセットに常に(何らかの形で)付随していなければならないことを意味する。
真実(データの正確さ)を保証するために、監査手続きやその他の管理が行われる必要がある。
システムが継続的なデータ収集のために設計されている場合(一回限りではなく)、性能の監視と改善のための追加的なプロセスを設ける必要がある。
7.1.2. レベル 2:形式化されている
成熟度モデルの第2レベルは、可能な限り、文書とメタデータが業界標準のフレームワークに従っていることを要求することで、第 1 レベルを包含し広がっている。レベル2は、許容できる成熟度の最小限のレベルと考えるべきであるが、新規のデータ型については例外が生じる可能性がある。標準の使用を推奨することは、メタデータにも適用される。
7.1.3. レベル3:実装されている
業界標準のDQプロセスを自動的かつ設計的に実施するシステムが導入されている。標準化のサポート(例:リファレンスデータ管理)を含む、データ管理をサポートするための様々なインフラが整備されていること。ヒューマンエラーの範囲を減らすことにより、そのような実装は一般に信頼性(Reliability)と一貫性(Coherence)を向上させることができる(例えば、 相互作用する複数のプロセスに関して)。このような実装は、適時性(Timeliness)を保証するためにも必要であり、メタデータが可能な限りデータ生成イベントの近くで設計により収集されることを保証するものでなければならない。
7.1.4. レベル 4:自動化されている
上記のシステム及びインフラの運用及びアウトプットは、下流で直接利用するためのデータ及び DQ 要素を統一するため、機械可読であるべきである。メタデータはFAIRの原則に従って表現されるべきである。これは野心的なレベルであることを意図している。
7.2. 本質的な決定要因:推奨事項及び成熟度レベル
データがどのように収集または生成されたかを示す文書化されたエビデンスを超えて、我々は通常、DQの内在的側面の測定値を適用することができる。これらはデータセットから直接導き出すことができるが、その計算には外部の知識体系に依存することもできる。
7.2.1. レベル0:本質的
エビデンス生成に使用する前に、どのようなエビデンスも評価できるため、品質に関する確固たる最小要件は存在しない。しかしながら、関連する品質評価なしにデータを広めることは推奨されない。
7.2.2. レベル 1:メタデータ
データには、メタデータとして一連の品質評価指標が提供される。これらのデータの中には、データセットから直接得られるものもあれば、データ収集プロセス全体から得られるもの(サンプリング、バイアスなど)もある。メタデータは、その解釈に必要なデータ要素の記述もカバーする必要がある。
7.2.3. レベル 2:標準化されている
データセット間で比較できるような、標準化された品質指標のセットが提供されている。可能であれば,標準はデータセットが表すべきものに関して評価するために用いることのできる参照知識までカバーされるべきである(例えば,偏りを評価するための典型的な母集団の分布など)。メタデータは共有定義を利用することで、データセット間の比較と統合を可能にする。
7.2.4. レベル 3: 自動化されている
品質評価が自動化されている(少なくとも多くの評価指標について)。一般に、これはデータが共通のデータモデルで表現され、標準的なテストライブラリが受信データに対して実行できる場合にのみ実現可能である。データとメタデータはFAIRの原則に従うべきである。
7.2.5. レベル4:フィードバック
データ利用者による品質評価が、データ収集・作成プロセスを改善するためのフィードバックを提供できるようなデータエコシステムがある。
(なお、レベル 2 とレベル 3 の成熟度の順番は、特定のデータ型では変わることがある)
7.3. データ品質に関する質問固有の側面に対する推奨事項と成熟度レベル
一般に、対象となる問い無しには、データセットの関連性(relevance)、およびExtensivenessと精度(precision)の側面を評価することは不可能である。しかし、規制当局の意思決定に大規模なデータを採用し、主要なユースケース以外での利用を考える場合、関連性(relevance)を含むDQをどの程度まで「事前」に評価できるかを明確にすることが重要になる。
7.3.1. レベル 1: アドホック
問い固有のすべてのディメンションは、「クエリ時」にのみ、アドホックに評価される。
7.3.2. レベル2: ドメイン定義(domain-defined)
一般的な問いの範囲が特定され、そこから許容レベルの品質を保証するために使用できる評価指標と閾値が導き出される。データカタログで公開されるデータは、このような評価指標を利用する必要がある。
7.3.3. レベル 3:質問定義(question-defined)
特定の問いに対する要件は、正確に成文化され、特定の問いに対するデータセットの関連性を自動的に評価できるような方法にて測定基準や閾値をマッピングできる。これは一次利用の場合では当然のレベルであり、二次利用では理想的なレベルとして意図されるべきである。
7.4. ソースでの品質
一般的なガイドラインとして、データの収集・生成プロセスを設計する際には、DQの側面について可能な限り早期に対処することが望まれる。例えば、生成の瞬間に近い段階で品質を評価することで、収集エラーを修正することができる。データが元の文脈から離れれば離れるほど、問題を修正することは難しくなる。データ生成の文脈に関する知識はそのデータが生成される時が最も多いため、これは特にメタデータに関連することになる。
7.5. QMSの役割
品質管理システム(QMS)[1,3]は、品質方針と目標を達成するためのプロセス、手順、責任を文書化した、組織が採用する公式なアプローチである。QMSは、品質計画、品質保証、品質管理及び品質改善を通じて、これらの品質目標を達成する。DQプロセスは、可能な限り、標準的なQMSの文脈で組み立てられるべきである。特に、ISO9000シリーズのような規格は、業界を超えたQMSを定義しており、より具体的なQMSは特定の業界や製品向けに開発されている(例えば、ソフトウェア製品向けのISO2500)。
8. 意思決定のためのデータの規制的利用
ここで紹介する一般的なフレームワークは、医薬品の評価やモニタリングの文脈で、データ解析によって得られたエビデンスに基づく規制当局の意思決定に幅広く適用されることを意図している。このうち、本 DQF に関連して特に重要な分野として、生物学的分析オミックスデータ、動物衛生データ、 前臨床データ(細胞系及び動物系実験データ)、副作用自発報告データ、化学及び製造管理データなどが挙げられている。
9. 参考文献
[1] European Health Data Space Data Quality Framework, Deliverable 6.1 of TEHDAS EU 3rd Health Program (GA: 101035467). May 18th, 2022, accessed at https://tehdas.eu/results/tehdas-develops-data-quality-recommendations
[2] ISO 9001:2015 Quality Management System, accessed at https://www.iso.org/standard/62085.html
[3] Kahn MG, et al. A Harmonized Data Quality Assessment Terminology and Framework for the Secondary Use of Electronic Health Record Data. EGEMS (Wash DC). 2016 Sep 11;4(1):1244. doi: 573 10.13063/2327-9214.1244.
[4] Healthcare Data Quality: A 4-Level Actionable Framework [Internet]. 2020 [cited 2022 Sept 5th]. Available from: https://www.healthcatalyst.com/insights/healthcare-data-quality-4-level-actionable-framework
[5] Schmidt CO, Struckmann S, Enzenbach C, Reineke A, Stausberg J, Damerow S, et al. BMC Framework – Facilitating harmonized data quality assessments. A Data Quality Framework for observational health research data collections with software implementations in R. BMC Medical Research Methodology. 2021 Apr 2;21(1):63.
[6] Sentinel QA Program. Quality Assurance – Sentinel Version Control System [Internet]. [cited 2022 Feb 14]. Available from: https://dev.sentinelsystem.org/projects/QA/repos/qa_package/browse
[7] NESTcc. Data Quality Framework, A report of the Data Quality Subcommittee of the NEST Coordinating Center – An initiative of MDIC [Internet]. 2020 [cited 2022 Feb 14]. Available from: https://nestcc.org/nestcc-data-quality-framework
[8] The National Patient-Centered Clinical Research Network. PCORnet – Data Quality Framework [Internet]. [cited 2022 Feb 18]. Available from: https://pcornet.org/data
[9] Duke-Margolis Center for Health Policy. Characterizing RWD Quality and Relevancy for Regulatory Purposes [Internet]. 2018. Available from: https://healthpolicy.duke.edu/sites/default/files/2020-03/characterizing_rwd.pdf
[10] Duke-Margolis Center for Health Policy. Determining Real-World Data’s Fitness for Use and the Role of Reliability [Internet]. 2019. Available from: https://healthpolicy.duke.edu/sites/default/files/2019-11/rwd_reliability.pdf
[11] Big Data Steering Group, Big Data Workplan 2022-2025. [Internet] 2022. Available from: https://www.ema.europa.eu/en/news/big-data-use-public-health-publication-big-data-steering-group-workplan-2022-25
[12] European Commission. Can we use data for another purpose? [Internet, cited 27 Sept 2022] https://ec.europa.eu/info/law/law-topic/data-protection/reform/rules-business-and-organisations/principles-gdpr/purpose-data-processing/can-we-use-data-another-purpose_en[12] American Society for Quality. What is a Quality Management System (QMS)? | ASQ [Internet]. [cited 2022 Feb 18]. Available from: https://asq.org/quality-resources/quality-management-system

